Ressourcerne er altid knappe, men truslerne venter ikke. Derfor handler “step 2” i en moden cybersikkerhedsindsats om at omsætte ambitioner til en konkret prioriteret plan, der kan gennemføres i drift, uden at organisationen drukner i dokumenter og møder.
I denne artikel får du en 30/60/90-dages strategi med klare leverancer, en enkel RACI light (hvem ejer hvad), samt praktiske tommelfingerregler for, hvad du gør først, når du skal løfte sikkerhed, compliance og beredskab på samme tid.
Hvad er en handlingsplan for cybersikkerhed, og hvorfor betyder den noget?
En handlingsplan for cybersikkerhed er en prioriteret liste af tiltag, der reducerer risikoen for driftsstop, datatab og misbrug af adgang, typisk fordelt på tid og ejerskab. Den betyder noget, fordi den skaber fælles retning mellem IT, ledelse og forretning, så I kan levere målbar risikoreduktion før I har perfekte politikker.
Mini-konklusion: Hvis I ikke kan pege på de tre vigtigste risici og de fem vigtigste aktiver, prioriterer I sandsynligvis efter støj frem for effekt.
Prioriteringslogik: sådan vælger du det rigtige næste skridt
Når ressourcer er knappe, skal prioritering være brutal og gennemsigtig. Brug tre filtre: 1) konsekvens for drift og borgere/kunder, 2) sandsynlighed ud fra kendte angrebsmønstre, og 3) gennemførbarhed på 30–90 dage med jeres bemanding og leverandørsetup.
De fem spørgsmål, der skærer igennem
- Hvilke systemer kan vi ikke undvære i 24–72 timer?
- Hvor kan en angriber få privilegeret adgang hurtigst?
- Hvilke leverandører kan lamme os, hvis de svigter eller kompromitteres?
- Har vi logs nok til at opdage noget, før pressen gør?
- Kan vi gendanne et kritisk system, og har vi testet det?
Hvad koster det, og hvordan estimerer du uden at gætte?
Omkostninger afhænger mest af kompleksitet og integrationsbehov, ikke af hvor “smart” værktøjet er. Estimér i tre spande: interne timer (IT og forvaltninger), leverandørkøb (MFA, logplatform, backup), og procesarbejde (playbooks, øvelser). Prioritér altid tiltag med lav indføringsfriktion og høj effekt, fx MFA på administratorer, baseline-logging og restore-test.
Mini-konklusion: Når I kan forklare prioriteringen i én sætning pr. tiltag, får I hurtigere ledelsesopbakning og færre sidespor.
RACI light: hvem ejer hvad i praksis?
Du behøver ikke et tungt governance-setup for at komme i gang, men du skal have tydelighed om ansvar. Brug en enkel RACI light, hvor “ejer” betyder beslutningsret og opfølgning, og “bidrager” betyder udførelse eller input.
- IT: ejer tekniske kontroller (MFA, logging, backup), bidrager til leverandørkrav og beredskab.
- Ledelse: ejer risikobeslutninger, prioritering og accept af rest-risiko, bidrager til kommunikation og kultur.
- Forvaltninger/fagområder: ejer forretningskritikalitet, proceskrav og konsekvensvurdering, bidrager til assetkort og øvelser.
- Indkøb: ejer kontraktspor, databehandlerkrav og SLA’er, bidrager til leverandørkortlægning og opfølgning.
Mini-konklusion: RACI light fjerner den klassiske flaskehals, hvor IT ender med at “eje alt”, men kun kan ændre halvdelen.
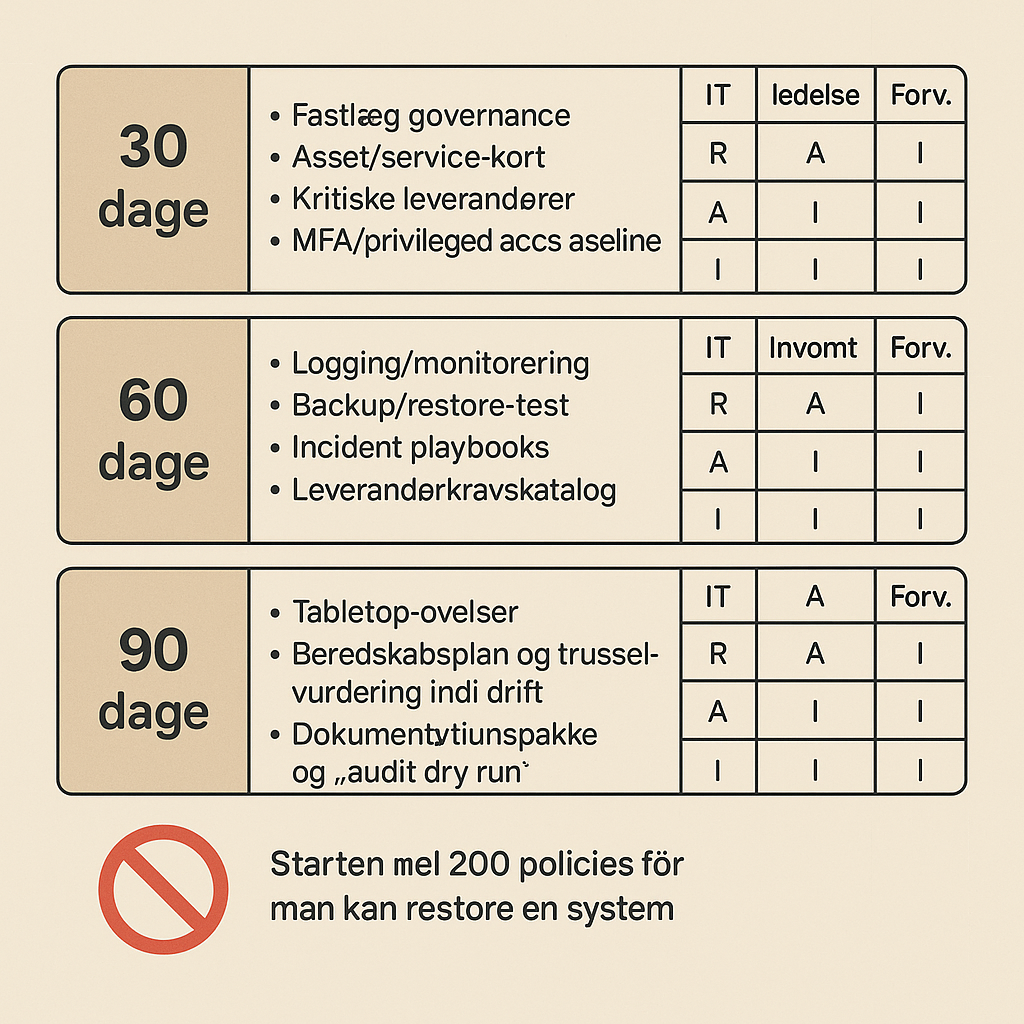
0–30 dage: governance, overblik over aktiver og en adgangs-baseline
De første 30 dage handler om at skabe styring og overblik, så de næste 60 og 90 dage ikke bliver tilfældige projekter. Målet er ikke komplet kortlægning, men en brugbar “topliste” over det, der kan vælte driften.
Fastlæg governance, beslutningsfora og rytme
Start med en enkel kadence: ugentlig 30-minutters sikkerhedsstyregruppe (IT + ledelse + indkøb) og en månedlig forretningsgennemgang med forvaltninger. Definér, hvad der kræver ledelsesbeslutning (fx nedetid, budget, risikovillighed) og hvad IT må eksekvere selv (fx MFA på admin-konti).
Asset/service-kort og kritiske leverandører
Lav et servicekort for 10–15 kritiske services: hvad hedder servicen, hvem bruger den, hvilket system understøtter den, hvor ligger data, og hvem er leverandør. Identificér derefter de 5–10 mest kritiske leverandører: driftspartner, EDR, mail, løn, fagsystemer, netværk.
Mini-konklusion: Et “godt nok” servicekort slår et perfekt CMDB-projekt, hvis I skal kunne prioritere sikkerhedstiltag hurtigt.
MFA og privileged access baseline
Indfør en baseline for privilegeret adgang: MFA på alle admin-konti, fjern delte konti, og gennemgå gruppemedlemskaber i AD/Azure. Hvis I har et PAM-værktøj, så start med de mest privilegerede brugere; hvis ikke, så lav stram proces for midlertidige admin-rettigheder og logning af ændringer.
31–60 dage: minimum logging, restore-test og hændelsesplaybooks
Nu skal I kunne opdage og reagere. Mange organisationer investerer i sikkerhedsværktøjer uden at sikre, at data faktisk kommer ind, eller at nogen kigger på alarmerne. Sæt derfor et minimumsniveau, der passer til jeres kapacitet.
Logging og monitorering: “minimum viable detection”
Definér 8–12 logkilder som et minimum: identitetslogs, admin-ændringer, mail-sikkerhed, EDR/antivirus, firewall/VPN, samt kritiske servere. Aftal hvem der triagerer alarmer, og hvor hurtigt. Hvis I ikke har SOC, så lav tidsvinduer og eskalationsveje, så alarmer ikke lander i en fælles postkasse.
Midt i denne fase giver det mening at støtte sig til en konkret ramme, fx en handlingsplan NIS2, så krav og leverancer hænger sammen uden at I bygger et bureaukratisk monster.
Backup og restore-test: det billigste, der virker
Backup er kun en udgift, indtil I tester restore. Prioritér 2–3 kritiske systemer, og gennemfør en restore-test fra end-to-end, inkl. adgang, netværk og applikationslag. Dokumentér RTO/RPO som realiteter, ikke ønsketænkning, og afklar om I har offline/immutability, så ransomware ikke sletter jeres redningsplanke.
Incident playbooks og leverandørkravskatalog
Lav korte playbooks på 1–2 sider for de mest sandsynlige hændelser: kompromitteret konto, ransomware, datalæk og leverandørnedbrud. Samtidig skal indkøb og IT samle et leverandørkravskatalog: MFA-krav, logadgang, underleverandører, patchvinduer, hændelsesvarsling og dokumentation.
Mini-konklusion: Hvis I kan opdage, stoppe og gendanne på de vigtigste services, har I reduceret risikoen mere end 50 sider nye politikker kan.
61–90 dage: øvelser, beredskab i drift og “audit dry run”
De sidste 30 dage i planen handler om at gøre arbejdet robust: øve samarbejdet, bygge beredskab ind i driften og samle dokumentationen, så den kan tåle både intern revision og et kritisk spørgsmål fra ledelsen.
Tabletop-øvelser: træn beslutninger, ikke PowerPoints
Kør mindst to tabletop-øvelser: én om ransomware med driftstab, og én om datalæk med ekstern kommunikation. Inkludér IT, ledelse, kommunikation, forvaltninger og indkøb. Øvelsen skal munde ud i konkrete forbedringer: hvem ringer til leverandøren, hvem godkender nedlukning, og hvem beslutter betaling/ikke betaling.
Beredskabsplan og trusselvurdering ind i drift
Opdatér beredskabsplanen, så den afspejler jeres faktiske services og leverandører. Lav en enkel trusselvurdering baseret på aktuelle angreb (phishing, MFA-træthed, misbrug af admin, udnyttelse af sårbarheder). Indbyg derefter i drift: månedlig patch-status, kvartalsvis adgangsreview, og faste tests af backup.
Dokumentationspakke og “audit dry run”
Saml en dokumentationspakke med det, I faktisk gør: servicekort, RACI, logkilder, restore-resultater, playbooks, leverandørkrav og øvelsesreferater. Kør en “audit dry run”, hvor én person stiller kravspørgsmål, og én finder beviser. Det afslører huller, før en ekstern part gør det.
Mini-konklusion: Når øvelser og evidens sidder i kalenderen, går sikkerhed fra projekt til praksis.
Typiske fejl og faldgruber, og sådan undgår du dem
De mest almindelige fejl kommer ikke af manglende vilje, men af uklar prioritering og uklart ejerskab. Her er de klassiske snubletråde og modtræk:
- For bred scope: afgræns til kritiske services først, udvid derefter.
- Værktøjsjagt: køb ikke en SIEM, før I har defineret logkilder og responsflow.
- Ingen restore-test: planlæg test tidligt, og accepter at første test ofte fejler.
- Leverandører uden krav: få krav ind i kontrakter og SLA’er, ikke kun i e-mails.
- Urealistiske RTO/RPO: forhandl realistiske mål med forretningen og dokumentér beslutningen.
- Playbooks uden øvelse: tabletop er billigere end kaos under en reel hændelse.
Mini-konklusion: Hver faldgrube kan oversættes til ét simpelt princip: gør det målbart, gør det øveligt, og gør det ejet.
Bedste praksis for løbende prioritering, når alt haster
Når du har gennemført 90-dages planen, kommer den svære del: at holde kursen. En praktisk metode er at køre en fast, lille portefølje med 5–7 sikkerhedsinitiativer ad gangen og lukke noget ned, før I starter nyt.
- Hold en månedlig “risk review” med ledelsen: top 5 risici og status på kontroller.
- Brug en enkel score for hvert tiltag: effekt, indsats, afhængigheder.
- Indfør “definition of done”: fx MFA slået til, testet, dokumenteret og kommunikeret.
- Gør leverandøropfølgning til drift: kvartalsvis status, ikke ad hoc brandslukning.
- Automatisér det gentagelige: adgangsrapporter, patch-oversigter, backup-alarmer.
Mini-konklusion: Kontinuitet kommer ikke af flere projekter, men af færre, der faktisk bliver gjort færdige.
Hvad du ikke skal gøre: politikker før gendannelse
Det frister at starte med at skrive 200 policies, fordi det føles kontrollerbart og “compliant”. Men hvis I ikke kan gendanne et system, hvis en admin-konto kompromitteres, eller hvis I ikke kan se i logs hvad der skete, så er papir en falsk tryghed. Prioritér derfor teknisk baseline, restore-test og øvet beredskab før detaljerede regelværk, og skriv kun de politikker, der understøtter det, I allerede har sat i drift.




